When a PDF file is created by a scanner, all the contents will be captured as an image instead of text data. So normal PDF converter app without OCR function can only output an image instead of selectable and editable text contents in Microsoft Office apps.
With advanced OCR function, our OCR converter app, including PDF to Word OCR andPDF Converter OCR for Windows can extract perform text recognition and extract text contents out of scanned documents.
However, OCR result is related to many factors. One study based on recognition of 19th- and early 20th-century newspaper pages concluded that character-by-character OCR accuracy for commercial OCR software varied from 71% to 98%. (Wikipedia). Our OCR app can recognize the text as accurately as possible, but it can’t guarantee 100% accuracy either.
A few tips for improving OCR accuracy:
1. Rotate the page to the correct orientation.
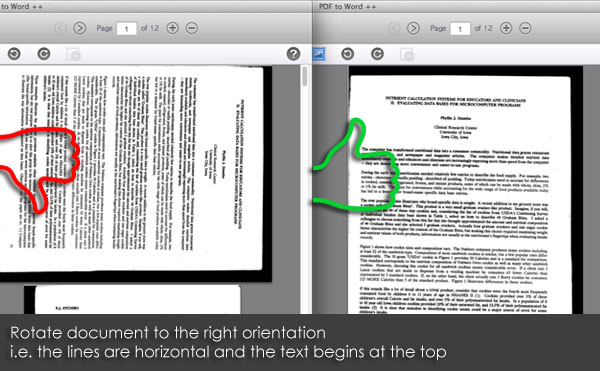
OCR will perform text recognition from left to right, and from top to bottom, so OCR accuracy will decrease if a PDF file was rotated. Rotate the page to the correct orientation is important. Move your mouse cursor to the top of the built-in PDF Reader, you’ll see ‘Rotate’ button.
2. Increase scanned document’s quality
Higher image quality can increase OCR accuracy. The scanned image in 300 dpi or above is recommended. So try to increase the dpi before creating a PDF file by the scanner.
OCR always prefers a neat and clean PDF document.
3. Select the correct document language
If your PDF file is in Italian, but you choose ‘English’ as OCR option, our app can’t recognize text contents correctly. So please remember to choose the appropriate document language prior to OCR conversion.
The application supports 10 languages, including English, French, German, Italian, Spanish, Portuguese, Polish, Swedish, Russian and Dutch.
4. Select image areas
Graphic contents will affect OCR accuracy. If the scanned PDF file contains image elements, please select them prior to the OCR conversion.
(1) To select image areas, move your mouse cursor to the built-in reader, hold left-click and drag to select an area. And then release the mouse.
(2) To move or adjust the area, click on it and drag the area border to the desired location.
(3) To remove the selected area, move your mouse cursor to the left top of the built-in PDF reader, you’ll see ‘remove’ buttons appear. You can remove single selected areas, or all the selected areas in this document.
The selected area will be preserved as an image in converted Word document and the app will not perform OCR for the select areas. By doing this, you can keep the original layouts better. If you don’t select image area, text on the image will also be OCRed, but the image will be missing in output document.
Related tutorial:
How can you distinguish scanned PDF from normal PDF file? >>