PDF document (Portable Document Format) can be created from various sources and by different devices or software, so they are not always the same. Scanned PDF is a typical example, sometimes it looks like the normal PDF file created from Word, but actually when you scan a paper using a scanner, the whole content will be captured as an image. So when you save it as PDF file, there’s no text content but only an image embedded in the PDF file.
In this case, if you want to convert scanned PDF into editable & searchable Word document, you need to choose the right PDF Converter. Optical character recognition (OCR) is needed for recognizing and extracting data from the image.
But how can we distinguish scanned PDF from the normal file? Sometimes they just look like the same thing. Here are some methods:
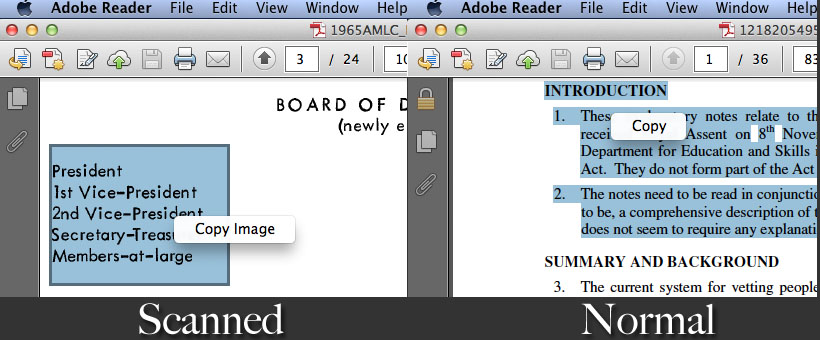
1. Select Text
You can’t select any text from scanned PDF, you can only select an area of the image. But you can select and copy text from normal PDF.
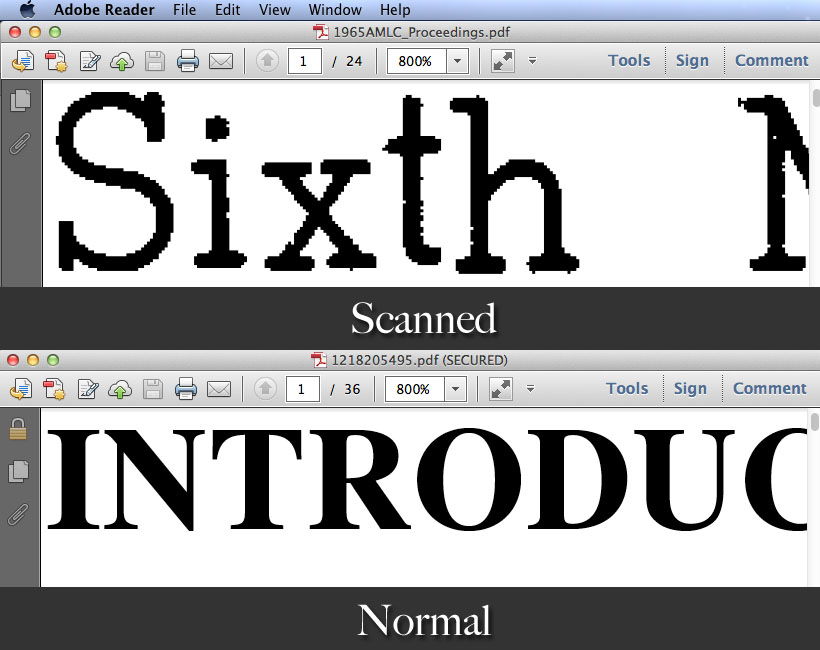
2. Zoom in
Try to enlarge the PDF file, content in scanned PDF will blur and pixelate. But in a normal PDF file, even if you enlarge the document to billboard size, text can keep the same crisp quality.
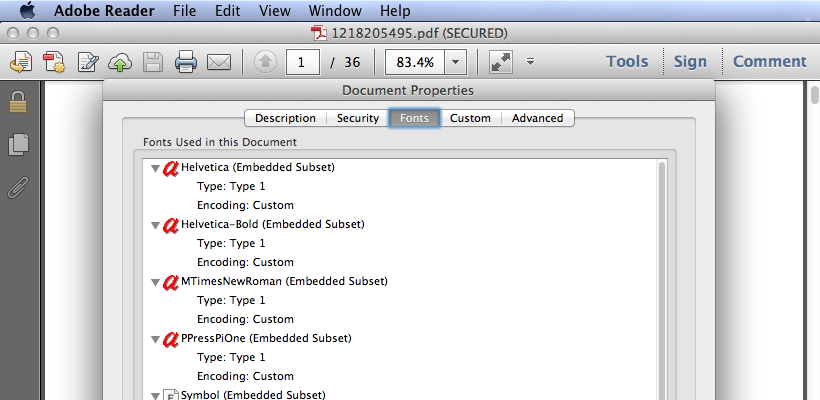
3. Check document properties
If you open a scanned PDF in Adobe Reader, you’ll see there’s no fonts information in document properties. PDF Converters without OCR function can not recognize text in the 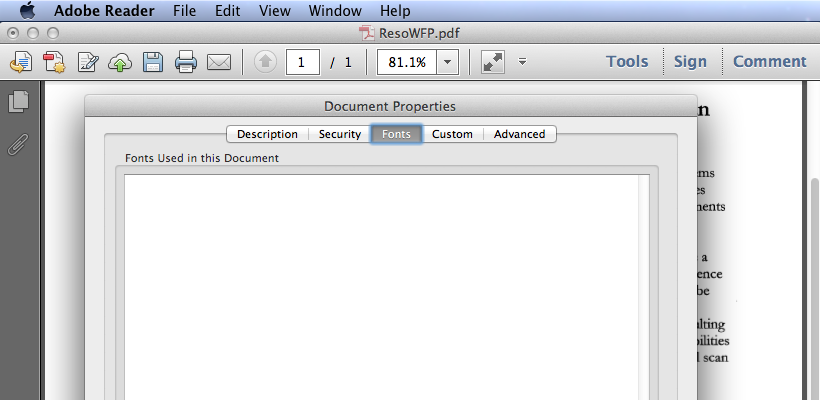 scanned PDF file, so they can only output image instead of editable content.
scanned PDF file, so they can only output image instead of editable content.
But if you open a normal PDF with text data, you can find fonts used in this document in Document Properties.