Encoding Issue for a PDF conversion:
For some particular PDF file, the output Word document does not display correctly after converting to Microsoft Word, Excel or PowerPoint.
*Text is garbled or displays as gibberish characters;
*Some certain letter combination is replaced with strange symbols, e.g. ff becomes @, ie becomes $, space becomes %;
*Text does not display correctly.
The reason that caused the encoding problem:
Within text strings in PDF, characters are shown using character codes that map to glyphs in the current font using an encoding. There are a number of encodings, a font can even have its own built-in encoding. Encoding is must-have information for PDF conversion task. If the fonts in PDF don’t use a standard encoding for mapping the glyph indices to characters, or the encoding info of the font is missing, you’ll get garbage characters after converting it to Word.
The same problem not only happens in PDF conversion, if you can try to open this type of PDF file with Adobe Reader, Preview, or any other PDF readers, copy a word or a sentences and then paste it to the default text editing app, such as ‘TextEdit’ on Mac or ’Notepad’ on Windows, you’ll get the same result. The system is not able to display those characters without correct encoding information.
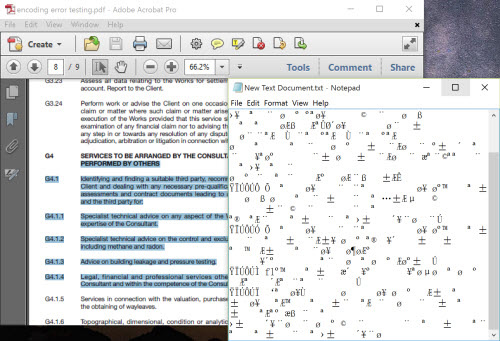
Lighten PDF Converter apps will first analyze the PDF data, including the font and encoding info, if it can’t recognize the correct encoding, then it is not able to decide which character should write into Word document.
Solution for PDF with encoding problem:
If the operating system is not able to display the content correctly, none of the PDF converter software can deal with this type of document. So we are not able to solve this problem in normal PDF conversion mode, unless you provide another PDF file or recreate the PDF using other PDF creator software.
But you can convert this type of PDF with OCR function. OCR treats the whole page as image, and it can perform text recognition and extraction. The output formatting may not be well kept, and some similar text characters such as ‘0’ & ‘O’, ‘I’ & ‘1’ may not be converted correctly. But it can bypass the original encoding using in PDF.