Issue:
The output Word document is uneditable after converting it to Word with PDF Converter, it contains an image only, I can’t edit the content, what should I do?
Reason:
If your PDF file is a scanned document, this problem will happen. You’ll get a notification message saying ‘This PDF document contains image-only or scanned pages’ after conversion.
Why? When we create a PDF file from a scanner, the scanner will only capture everything as an image, and put each page as an image into the PDF document. There’s no font and text information within the PDF data. So Lighten PDF Converter can only output the image in the output Word document instead of editable text content.
How do you decide if the PDF contains scanned pages? It looks like it has text content only.
Please open this PDF file with ‘Adobe Reader’ or other PDF readers, if you are on Mac OS X, open it with ‘Preview’. And then try to select some text. If you can select a certain word or a sentence, that means your PDF file has text info. If you can only select the whole page, then the PDF file is image-only.
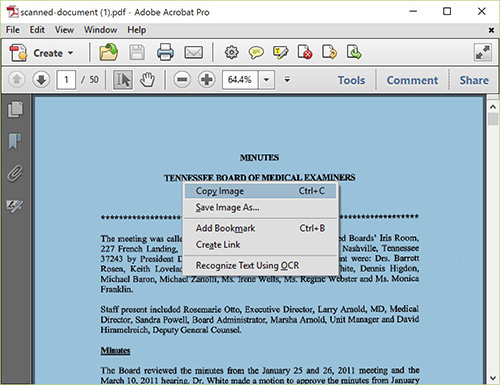
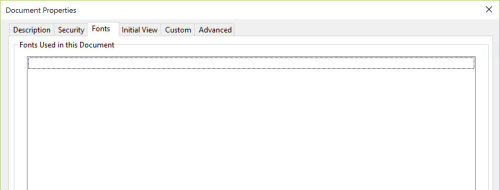
If you have Adobe Reader, open the PDF file, click ‘File’ -> ‘Properties’, click the ‘Font’ tab, you can see there’s no font data.
This article showing you how to tell if your PDF file a normal PDF or a scanned one. Learn More>>
Solutions:
What can I do when I want to convert scanned PDF to editable Word document?
OCR function is needed for converting this type of document. OCR is a technology which can recognize text characters from images base on their shapes and looks, and extract text content.
Lighten PDF Converters have OCR version, for both Mac and Windows version, it’s available for PDF Converter Master, PDF to Word Converter, both Mac and Windows versions. If you’ve already purchased standard version, you can purchase OCR upgrade at a discounted price from the standard version.
How does OCR work?
It’s not an easy task, we’ll know letter ‘a’ is ‘a’ instantly because of our smart human brain, but PDF Converter needs to perform complex calculation, compare the shapes it recognized with the database, to look up the similar shapes, and decide which letter should be extracted. So mistakes may happen during the OCR process, some similar text characters such as ‘i’ & ‘l’, ‘O’ & ‘0’ may not be recognized correctly. For better conversion accuracy, the scanned image should be clear enough, black text on a white background, and the page orientation should be correct. This article showing you how to enhance OCR conversion accuracy. Learn More>>
If the OCR version of Lighten PDF Converter doesn’t convert your PDF file correctly, please feel free to send the original PDF file to our support team via support[at]lightenpdf.com, we will try to convert it for you and send it back ASAP.